
1. 全国文化財目録の概要
(1)システムの概要と背景
日本には、遺跡、建造物や有形文化財など膨大な文化財があります。それらの文化財に対し、同じ文化財であっても国・都道府県・区市町村・大学や博物館などそれぞれの機関から文化財に関するデータが作成されます。また、同じ文化財(主に遺跡)であっても、複数回の調査が実施されることがあります。
結果、同一の文化財に複数の情報や記録が生成されましたが、バラバラにあるため、一元的に確認することは難しい状況でした。
そこで、文化財単位に各情報を名寄せし、集約しました。
全国文化財目録(2023年12月7日公開)
URL: https://sitereports.nabunken.go.jp/ja/search-cultural-heritage
2. データと機能
(1)データ
下記のデータをもとに、名寄せ処理しました。
遺跡抄録データ 約14万件 https://sitereports.nabunken.go.jp/ja/search-site
遺跡データベース(更新停止)約48万件
国土交通省:都道府県指定文化財データ
文化庁:国指定文化財等データベース
各地方公共団体の文化財オープンデータ
(2)文化財ごとに名寄せ・洗い替え処理
文化財情報の構成として、Monument-Event-Archiveという階層があります。Monumentは、文化財そのもの、Eventは調査自体の記録、Archiveは具体的な成果物となります(図1)。現在、日本では統一的なMonument情報がありません。そこで、文化財の物件ごとに自動名寄せ※処理を実施しました。結果、文化財の物件単位として約51万件となりました(図2)。ただし、文化財名称が多様であり、自動名寄せが適切に実施できていないケースもあります。今後、改善を図っていきます。
また、名寄せ処理のために、文化財情報のうち、市町村コードについて洗い替え処理※を実施しました。
※名寄せ:複数のデータ源から重複している同一のデータを統合すること
※洗い替え:廃止となった市町村コードを新たなコードに更新しました
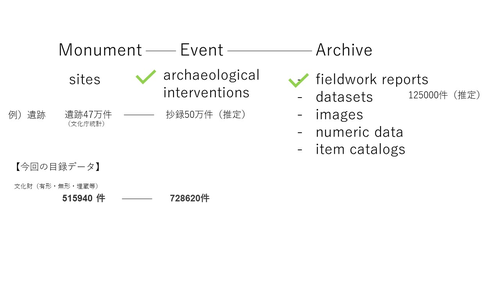
図1 文化財情報の構造
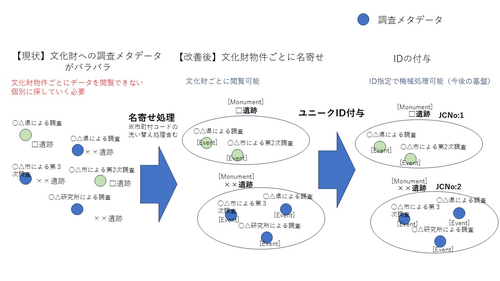
図2 文化財情報の名寄せ処理
3. 期待される効果
(1)アクセス性の向上:名寄せによって文化財情報を統合的に確認する
これまでは様々な機関が作成したデータを個別に捜索し、確認する必要がありました。当該文化財の情報を集約することで、当該文化財に関する情報を一覧で閲覧することができます(図3・4)。
(2)機械可読性の向上:文化財のID化による多様な展開への基盤
文化財ごとにIDを付与しました。文化財そのものを対象に、上位データのIDとして、一意となる日本全国文化財番号 (JC番号:JCNo)を付与しました。各個別の下位データにも一意となるIDを付与しました。IDを付与することで、今後のコンピュータ処理の際に、様々な展開や応用が可能となります。今回はその基盤化のための一歩となります。
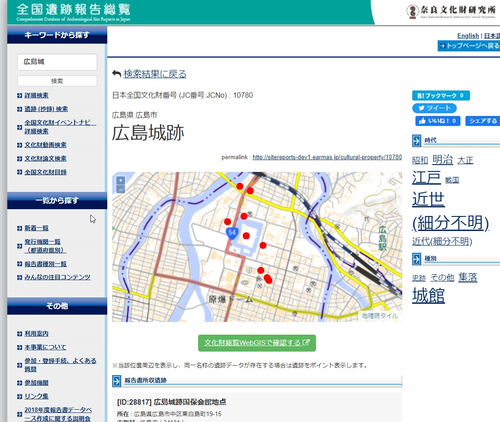
図3 文化財ごとに表示
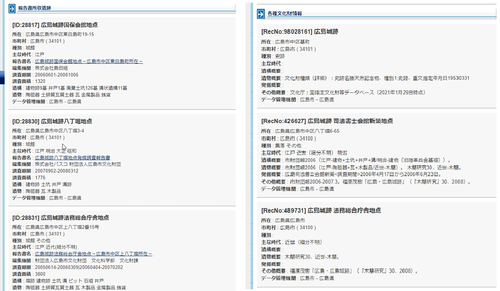
図4 調査情報を集約して表示
お問い合わせ先 奈良文化財研究所企画調整部 高田 Email: soran_nabunken@nich.go.jp